こんにちは、開発事業部で PM をしている丸山です。
キカガクでは昨年夏に GCP を中心としたデータ基盤へ移行しました。
データ基盤では現在次のように複数ソースのデータを BigQuery へ集約し、加工していくような構成を取っています。
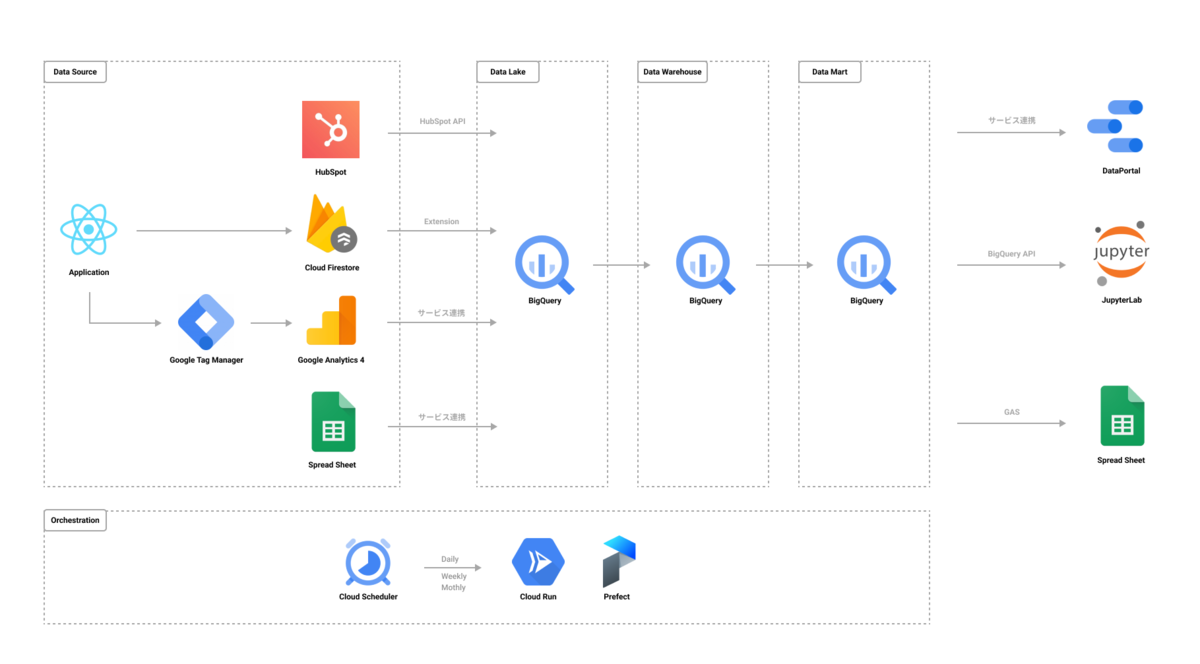
半年程度運用してデータパイプラインの管理のつらさが表面に浮かんでくる中で、上図にも記載があるワークフロー管理ツールの導入に踏み切ったのですが、その際に無秩序となっていた BigQuery のデータセット/テーブル構成に関してもテコ入れをしましたので、そちらの内容を書いていこうと思います。
前提
本題に入る前に、前提として今回扱っているデータ基盤は下記の規模感のものとなります。
- 扱うデータソース数 : 4 つ(Cloud Firestore, Hubspot, GA4, Google Spread Sheet)
- GSS は 10 ほどのデータソースがあります。
- データ基盤を直接触る人数 : 2 人
データ基盤の規模や活用のフェーズに応じて適切な Solution が異なるかと思うのですが、今回は小規模で活用する人数も少ないような初期フェーズのデータ基盤の話となりますので、ご承知おきください。
暗中模索な日々を送っており、もしもっとこうすると良いよ、とアドバイスがあればぜひコメントから教えていただけると泣いて喜びます!
状況
ゼロイチでデータ基盤を作成した状況から、データソースやデータパイプラインを継ぎ足していく中で、ファイル構造が無秩序なものとなってしまっていました。
データセットやテーブルの名称がデータソースを表すものもあれば、データを活用する目的を表すものもあり、色々と粒の揃っていない情報が混在する状況となってしまいました。
作成者の自分 1 人で触る分にはまだよいのですが、今後基盤を操作するメンバーが増えていった際に、確実に困惑することが想像されます。
整理整頓
そこで、次の Step で整理整頓を進めていきました。各ステップについて書いていこうと思います。
- (Step0: 前提知識)
- Step1: 整理の軸を決める
- Step2: 仕様を整理する
- Step3: 手段の整理
Step0: 前提知識
BigQuery のデータセット, テーブル整理にあたり、いくつか使用する専門用語について確認をします。
BigQuery のファイル構造は次のようになっています。
project
L dataset
L table, view
Project に dataset が紐付き、dataset に table が紐づくような構造です。table の下にさらに階層を掘ることはできず、この 3 つの概念で多様なデータを整理していく必要があります。
今回のケースは 1 つの Project で管理するため、実質 dataset と table の制約で情報を整理する必要がありました。
Step1: 整理の軸を決める
Step0 を踏まえた上で、まずは整理の軸を決めます。
今回は次の 6 つの軸を判断できるようにしたい、とします。
*()内はこの後の内容で軸を参照する時に使用する名前です。
データ層(dataLayer)
- まずはデータ層です。あるデータが「データレイク」「データウェアハウス」「データマート」のどの階層に位置するものかどうかを識別したいと考えました。
- これは、将来的にデータ基盤を扱う人数が増えた時に、A さんにはデータウェアハウス層以降を操作できる権限を付与、B さんはデータレイク層のデータを DWH 層へ加工できる権限を付与、といったようにデータ層に応じて権限管理を行いたい背景もあります。
データソース(dataSource)
- そのデータがどのデータソースから生じたものなのかどうかも必要です。
- もちろんデータ加工を行う中で、複数データソースのデータが混ざることも生じますが、それまではどこからやってきたデータなのかを識別できると嬉しいです。
サービスの種類(serviceType)
- キカガクではプロダクトをマイクロサービス化する方針が決まっています。その前提に立った時に、サービス A, サービス B, サービス C とどのサービスのデータなのかわかるようにしておかないと、特定のサービスの分析をする際に困ってしまいます。
ユーザーの種類(userType)
- キカガクのデータ基盤では DataPortal という BI ツールにダッシュボードを構築して、そこからビジネスサイドでのデータ活用を想定しています。
- その際に、ユーザーの種類(無料ユーザー、有料ユーザーなど)ごとにダッシュボードを構築しているため、データセットの段階でユーザーの種類で区切るようにしていました。
コレクション名(collectionName)
- Firestore の場合には、コレクション、サブコレクションごとにデータを吐き出すようなサービス連携をおこなっているため、データソースの下位概念として、どのコレクションから来たデータなのかも判別したいです。
テーブル固有名(name)
- また、各テーブルの固有の名前も必要となります。
- 例えば「いちご詰め放題イベント参加者情報」というGSSのデータから作成したテーブルの場合に
strawberry-event-participantsみたいな名前をつけるとしたら、これを指します。
(加えて、誰がデータを扱うかという情報も識別できると良いと考えていました。分析者が複数名現れた時に、それぞれの分析者が各々の専用の場所にアウトプットをおけるとよさそうです。)
Step2: 仕様を整理する
続けて、仕様としてこちら側ではどうにもできない内容を整理します。
今回は 2 つの仕様による制約がありました。
① Frestore Extensions で連携した場合のデータセット名, テーブル名
Firestore → BigQuery へのデータのエクスポートは次の Firestore Extension を使用しています。
Firebase Extensions | Stream Collections to BigQuery
これは大変便利で、Firestore のデータ更新のたびに Cloud Functions でデータを BigQuery へストリーミングインサートしてくれます。
これを使用している場合には、BigQuery では次のようなテーブル、ビュー名でデータが挿入される仕様となっています。
{collectionName}_raw_changelog
{collectionName}_raw_latest
* {}_raw_changelog は DB の変更ログ、{}_raw_latest は最新のログに絞ったテーブルです。
なお、どのデータセットへデータを転送するかどうかは、Extensions の設定で指定することができます。
② GA4 と連携した場合のデータセット名, テーブル名
GA4 と BigQuery の連携をした場合には、次のデータセット名、テーブル名でデータが転送されます。
analytics_{propertyId}
L events_YYYYMMDD
ここも制約として受け入れて、構成や命名規則を定めることとします。
Step3: 手段の整理
Step2 の制約を踏まえて、Step1 の情報をどういった手段を用いて整理することができるでしょうか。使える手段は大きく 3 つです。
① データセットの区切り方
整理したい軸の項目ごとにデータセットを作ることで、その軸での情報整理を行うことができます。
例えば、データソースでデータセットを次のように区切れば、どのデータソースかどうかは、データセット名を見ればわかることになります。
firestore
L xxxx
hubspot
L xxxx
ga4
L xxxx
gss
L xxxx
データセットを切るタイミングで、複数の整理軸を表現したい場合には、データセットの命名規則を定めることで可能です。
例えば、データソースとサービスの種類の 2 つの軸をデータセットの区切りで考慮したい場合には、{dataSource}_{serviceType} というルールを定めて、次のようにすることができます。
# {dataSource}_{serviceType} firestore_serviceA L xxxx firestore_serviceB L xxxx hubspot_serviceA L xxxx hubspot_serviceB L xxxx ...
③ テーブルの命名規則
同様に、データセットにぶら下げたテーブルについても命名規則を設けて情報を整理することができます。
# {serviceType}_{userType}_{name}
firestore
L serviceA_free_xxxx
L serviceA_paid_yyyy
結論
以上踏まえテックリードの方と相談した上で、最終的には次のような形で整理を行いました。
データセット名
- {dataLayer} と {DataSource} の情報を持たせる
- データレイク層のみデータセット名 = データソースとする
テーブル名
- データレイク層のデータセットのテーブルは自動で作成されるテーブル名となる
- DWH層のデータセットのテーブルは次の規則にする
{serviceType}_{dataSource}_{collectionName}_{userType}_{name}- collectionName は dataSource が Firestore の時のみつける
- userType は必要に応じてつける
- データマート層のデータセットのテーブル名は次の規則にする
{serviceType}_{name}
具体的には次のようになります。
# ------------------------------
# データレイク層
# ・データソースの数だけデータセットを作成
# ------------------------------
firestore
L {collectionName}_raw_changelog
L {collectionName}_latest
L {collectionName}_raw_changelog
L {collectionName}_latest
L ...
gss
L {name}
L {name}
analytics_xxxxx
L events_xxxxx
# ------------------------------
# DWH層
# ・ 1 つのデータセットを作成
# ------------------------------
warehouse
L serviceA_firestore_users_free
L serviceA_firestore_users_paid
L serviceA_gss_free_strawberry-event-participants
L ...
# ------------------------------
# データマート層
# ・目的, および分析ユーザーごとに作成
# ------------------------------
mart-dashboard
L {serviceType}_{name}
mart-maruyama
mart-sofue
まず、GA4 の仕様で、自動で GA4 は専用のデータセットが作成されてしまいます。そのため、データセットには「データレイクのみ」データソースを配置するようにしました。
またデータレイク、ウェアハウス、マートごとにアクセスできる権限管理を行えるように、データセットにはこの情報を持たせるようにしました。
データマートはダッシュボードのためのマートと、各個人の分析のアウトプットとしてのマートの 2 種類の用途が考えられたため、前者のマートは mart-dashboard というデータセット名に、後者のマートは mart-maruyama というように分析者(あるいはユーザーカテゴリ)をつけるようにして識別しています。
残りの識別したい情報は皆 DWH 層での内容であったため、warehouse データセット配下のテーブルの命名規則でカバーするようにしました。
なお、serviceType をデータセット名に使用することなども検討しましたが、過去に途中でサービス名が変更されることがあったため、名前を変更することのできないデータセット名に使用するのは危険だと判断しました。(BigQuery では知る限りではテーブル名は変更が可能ですが、データセット名は変更することができません。)
おわりに
無秩序な BigQuery のデータセット、 テーブル構成を整理整頓する話でした。
2022 年 3 月にこのような構成に変更をし運用をしていっています。今のところはスッキリしていて問題ないのですが、今後どんどんユーザーやデータソース等が増えていった中で課題が浮かび上がってくるかもしれません。
キカガクは組織とサービスが急成長中の会社です。
成長のフェーズに応じてデータ基盤も様々な課題にぶつかっていくことが考えられます。もし初期フェーズから成長過程のデータ基盤に携わっていきたい方がいらっしゃいましたら、ぜひあなたの力を貸してください。
最後まで目を通していただきありがとうございました。